Memory leaks are something every developer has to eventually face. They are common in most languages, even if the language automatically manages memory for you. Memory leaks can result in problems such as application slowdowns, crashes, high latency, and so on.
In this blog post, we will look at what memory leaks are and how you can avoid them in your NodeJS application. Though this is more focused on NodeJS, it should generally apply to JavaScript and TypeScript as well. Avoiding memory leaks helps your application use resources efficiently and it also has performance benefits.
👋 As you’re exploring memory leaks in Node.js, you might want to explore AppSignal for Node.js as well. We provide you with out-of-the-box support for Node.js Core, Express, Next.js, Apollo Server, node-postgres and node-redis.
Memory Management in JavaScript
To understand memory leaks, we first need to understand how memory is managed in NodeJS. This means understanding how memory is managed by the JavaScript engine used by NodeJS. NodeJS uses the V8 Engine for JavaScript. You should check out Visualizing memory management in V8 Engine to get a better understanding of how memory is structured and utilized by JavaScript in V8.
Let’s do a short recap from the above-mentioned post:
Memory is mainly categorized into Stack and Heap memory.
- Stack: This is where static data, including method/function frames, primitive values, and pointers to objects are stored. This space is managed by the operating system (OS).
- Heap: This is where V8 stores objects or dynamic data. This is the biggest block of memory area and it’s where Garbage Collection(GC) takes place.
V8 manages the heap memory through garbage collection. In simple terms, it frees the memory used by orphan objects, i.e, objects that are no longer referenced from the Stack, directly or indirectly (via a reference in another object), to make space for new object creation.
The garbage collector in V8 is responsible for reclaiming unused memory for reuse by the V8 process. V8 garbage collectors are generational (Objects in Heap are grouped by their age and cleared at different stages). There are two stages and three different algorithms used for garbage collection by V8.
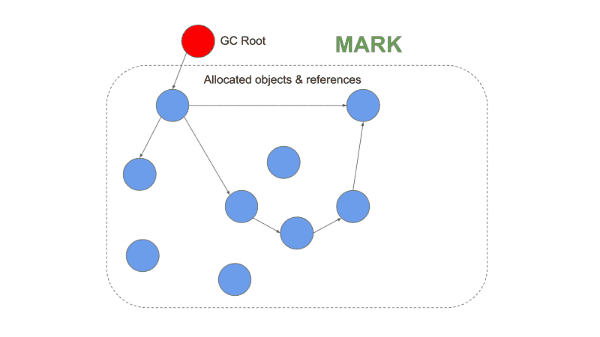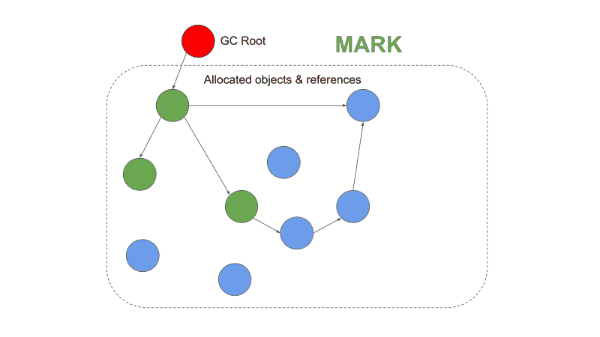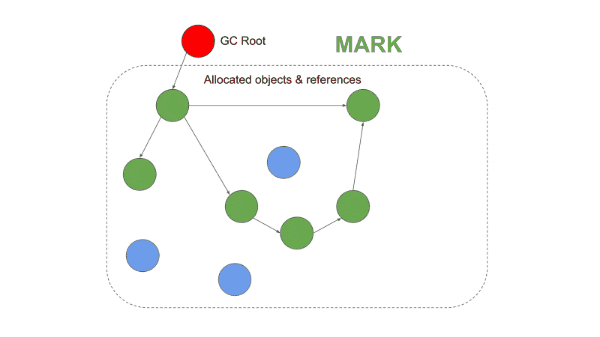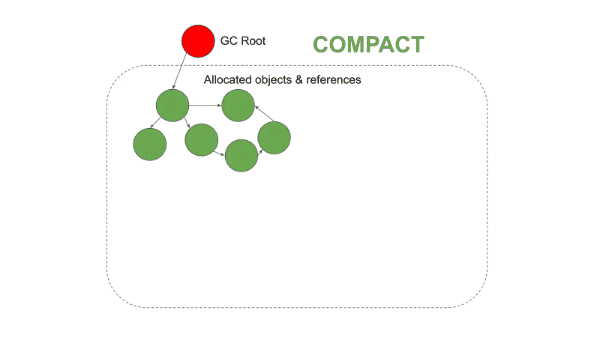
What Are Memory Leaks
In simple terms, a memory leak is nothing but an orphan block of memory on the heap that is no longer used by the application and hasn’t been returned to the OS by the garbage collector. So in effect, it’s a useless block of memory. An accumulation of such blocks over time could lead to the application not having enough memory to work with or even your OS not having enough memory to allocate, leading to slowdowns and/or crashing of the application or even the OS.
What Causes Memory Leaks in JS
Automatic memory management like garbage collection in V8 aims to avoid such memory leaks, for example, circular references are no longer a concern, but could still happen due to unwanted references in the Heap and could be caused by different reasons. Some of the most common reasons are described below.
- Global variables: Since global variables in JavaScript are referenced by the root node (window or global
this), they are never garbage collected throughout the lifetime of the application, and will occupy memory as long as the application is running. This applies to any object referenced by the global variables and all their children as well. Having a large graph of objects referenced from the root can lead to a memory leak. - Multiple references: When the same object is referenced from multiple objects, it might lead to a memory leak when one of the references is left dangling.
- Closures: JavaScript closures have the cool feature of memorizing its surrounding context. When a closure holds a reference to a large object in heap, it keeps the object in memory as long as the closure is in use. Which means you can easily end up in situations where a closure holding such reference can be improperly used leading to a memory leak
- Timers & Events: The use of setTimeout, setInterval, Observers and event listeners can cause memory leaks when heavy object references are kept in their callbacks without proper handling.
Best Practices to Avoid Memory Leaks
Now that we understand what causes memory leaks, let’s see how to avoid them and the best practices to use to ensure efficient memory use.
REDUCE USE OF GLOBAL VARIABLES
Since global variables are never garbage collected, it’s best to ensure you don’t overuse them. Below are some ways to ensure that.
Avoid Accidental Globals
When you assign a value to an undeclared variable, JavaScript automatically hoists it as a global variable in default mode. This could be the result of a typo and could lead to a memory leak. Another way could be when assigning a variable to this, which is still a holy grail in JavaScript.
1 2 3 4 5 6 7 8 9 10 | // This will be hoisted as a global variable function hello() { foo = "Message"; } // This will also become a global variable as global functions have // global `this` as the contextual `this` in non strict mode function hello() { this.foo = "Message"; } |
To avoid such surprises, always write JavaScript in strict mode using the 'use strict'; annotation at the top of your JS file. In strict mode, the above will result in an error. When you use ES modules or transpilers like TypeScript or Babel, you don’t need it as it’s automatically enabled. In recent versions of NodeJS, you can enable strict mode globally by passing the --use_strict flag when running the node command.
1 2 3 4 5 6 7 8 9 10 11 12 | "use strict"; // This will not be hoisted as global variable function hello() { foo = "Message"; // will throw runtime error } // This will not become global variable as global functions // have their own `this` in strict mode function hello() { this.foo = "Message"; } |
When you use arrow functions, you also need to be mindful not to create accidental globals, and unfortunately, strict mode will not help with this. You can use the no-invalid-this rule from ESLint to avoid such cases. If you are not using ESLint, just make sure not to assign to this from global arrow functions.
1 2 3 4 5 | // This will also become a global variable as arrow functions // do not have a contextual `this` and instead use a lexical `this` const hello = () => { this.foo = 'Message"; } |
Finally, keep in mind not to bind global this to any functions using the bind or call method, as it will defeat the purpose of using strict mode and such.
Use Global Scope Sparingly
In general, it’s a good practice to avoid using the global scope whenever possible and to also avoid using global variables as much as possible.
- As much as possible, don’t use the global scope. Instead, use local scope inside functions, as those will be garbage collected and memory will be freed. If you have to use a global variable due to some constraints, set the value to
nullwhen it’s no longer needed. - Use global variables only for constants, cache, and reusable singletons. Don’t use global variables for the convenience of avoiding passing values around. For sharing data between functions and classes, pass the values around as parameters or object attributes.
- Don’t store big objects in the global scope. If you have to store them, make sure to nullify them when they are not needed. For cache objects, set a handler to clean them up once in a while and don’t let them grow indefinitely.
USE STACK MEMORY EFFECTIVELY
Using stack variables as much as possible helps with memory efficiency and performance as stack access is much faster than heap access. This also ensures that we don’t accidentally cause memory leaks. Of course, it’s not practical to only use static data. In real-world applications, we would have to use lots of objects and dynamic data. But we can follow some tricks to make better use of stack.
- Avoid heap object references from stack variables when possible. Also, don’t keep unused variables.
- Destructure and use fields needed from an object or array rather than passing around entire objects/arrays to functions, closures, timers, and event handlers. This avoids keeping a reference to objects inside closures. The fields passed might mostly be primitives, which will be kept in the stack.
1 2 3 4 5 6 7 8 9 10 11 12 13 | function outer() { const obj = { foo: 1, bar: "hello", }; const closure = () { const { foo } = obj; myFunc(foo); } } function myFunc(foo) {} |
USE HEAP MEMORY EFFECTIVELY
It’s not possible to avoid using heap memory in any realistic application, but we can make them more efficient by following some of these tips:
- Copy objects where possible instead of passing references. Pass a reference only if the object is huge and a copy operation is expensive.
- Avoid object mutations as much as possible. Instead, use object spread or
Object.assignto copy them. - Avoid creating multiple references to the same object. Instead, make a copy of the object.
- Use short-lived variables.
- Avoid creating huge object trees. If they are unavoidable, try to keep them short-lived in the local scope.
PROPERLY USING CLOSURES, TIMERS AND EVENT HANDLERS
As we saw earlier, closures, timers and event handlers are other areas where memory leaks can occur. Let’s start with closures as they are the most common in JavaScript code. Look at the code below from the Meteor team. This leads to a memory leak as the longStr variable is never collected and keeps growing memory. The details are explained in this blog post.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 | var theThing = null; var replaceThing = function () { var originalThing = theThing; var unused = function () { if (originalThing) console.log("hi"); }; theThing = { longStr: new Array(1000000).join("*"), someMethod: function () { console.log(someMessage); }, }; }; setInterval(replaceThing, 1000); |
The code above creates multiple closures, and those closures hold on to object references. The memory leak, in this case, can be fixed by nullifying originalThing at the end of the replaceThing function. Such cases can also be avoided by creating copies of the object and following the immutable approach mentioned earlier.
When it comes to timers, always remember to pass copies of objects and avoid mutations. Also, clear timers when done, using clearTimeout and clearInterval methods.
The same goes for event listeners and observers. Clear them once the job is done, don’t leave event listeners running forever, especially if they are going to hold on to any object reference from the parent scope.
Conclusion
Memory leaks in JavaScript are not as big of a problem as they used to be, due to the evolution of the JS engines and improvements to the language, but if we are not careful, they can still happen and will cause performance issues and even application/OS crashes. The first step in ensuring that our code doesn’t cause memory leaks in a NodeJS application is to understand how the V8 engine handles memory. The next step is to understand what causes memory leaks. Once we understand this, we can try to avoid creating those scenarios altogether. And when we do hit memory leak/performance issues, we will know what to look for. When it comes to NodeJS, some tools can help as well. For example, Node-Memwatch and Node-Inspector are great for debugging memory issues.
References
- Memory leak patterns in JavaScript
- Memory Management
- Cross-Browser Event Handling Using Plain ole JavaScript
- Four types of leaks in your JavaScript code and how to get rid of them
- An interesting kind of JS memory leak
P.S. If you liked this post, subscribe to our new JavaScript Sorcery list for a monthly deep dive into more magical JavaScript tips and tricks.
P.P.S. If you’d love an all-in-one APM for Node or you’re already familiar with AppSignal, go and check out the first version of AppSignal for Node.js.
Our guest author Deepu K Sasidharan is the co-lead of the JHipster platform. He is a polyglot developer and Cloud-Native Advocate currently working as a Developer Advocate at Adyen. He is also a published author, conference speaker, and blogger.